The Spanner Paper
A Harbor In The Moonlight, Vernet
Every once in a while, an academic paper is published that really catches my eye. I’ve decided to write blog posts about these papers and I’m starting with the Spanner paper. The style of these posts is going to be mostly summarizing the information contained in the paper. Academic papers are very valuable, and the systems we use every day are often built from the ideas presented in them. It does take a good deal of patience and a lot of repetitions of reading papers to get the most of them. It’s a good exercise for me to summarize papers and as evidence from Papers We Love conference and the popularity of blogs like this one, people want to read summaries of these papers.
Background
This paper spends a good deal of time talking about the background and motivation for creating the Spanner system. The system was mostly developed to take care of three problems:
- Global Consistency
- Table-Like Schema
- SQL Query Language
Trying to accomplish these three things in a system at massive scale (Trillions of rows) required Google to come up with a novel architecture and some new APIs. Though non-trivial, building this system essentially enabled a distributed MySQL like environment with synchronous replication and the ability to scale to trillions of rows.
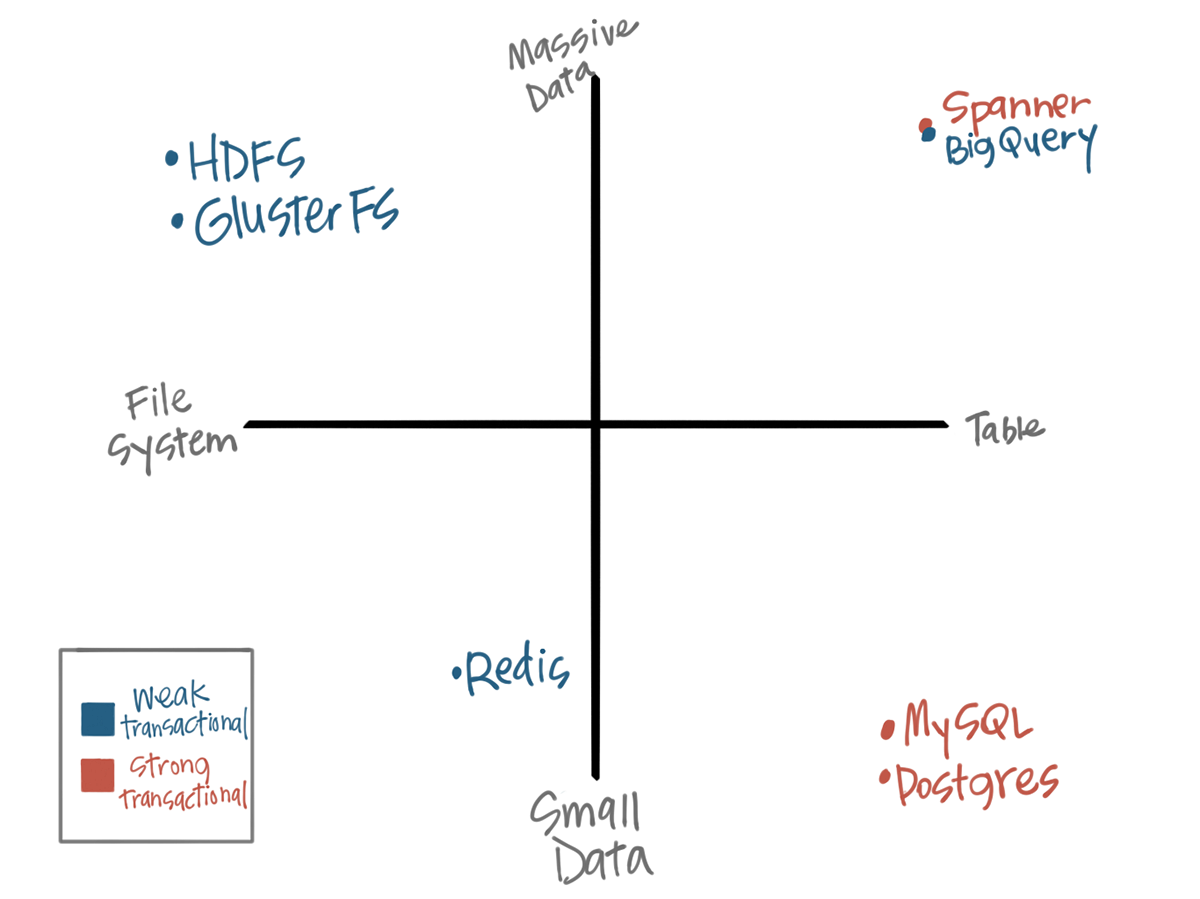
An example of the storage landscape
Spanner simplifies persistent storage in the "large data" ecosystem by allowing users the same administrative control they are used to in relational systems like MySQL, but supporting all the backend features necessary to build out to trillions of rows.
Global Consistency
The basic idea of Global Consistency is if a record is updated in one region (say, Asia) someone reading in another region (Say Africa) will have the same record updated on reading. It’s obvious why this wouldn’t be a requirement for most applications. If someone from a different time zone needs to refresh a few times to see your picture on Instagram, it doesn't matter at all. If you're dealing with a bank account, you have a different set of requirements on your hand. Spanner's desire is to be consistent in a global deployment, across many data centers.

An example of replicated sync in an async and a sync environment
Table-ish Schema
The paper stresses how important it was to support a table-like schema. Essentially, the overhead of converting data to and from a key-value store or file system is non-trivial and people (mostly application developers) don’t want to be bothered with it. You can’t really blame them, in a world where Excel is popular and more and more products enable SQL. You'd expect to use SQL anywhere where there is data. Furthermore, things like ODBC and JDBC are very nice and allow you to connect to your existing IDEs.

A rough example of a key-value representation to a table representation
TrueTime API
It took me a few reads through this section to get this but I think I got it. In order to guarantee synchronous replication within some interval of time, a lot has to go right from a machine perspective. Machines fail, networks fail and even clocks can fail. The Timestamp is an important aspect of the Spanner system as it allows Spanner's internal system to guarantee transactional consistency without being too disruptive to the clients. The TrueTime API was developed to get around the problems that occur when time is lost.

... In Paris by Kanye West & Jay-Z. Jay-z speaks of his Swiss watches losing time.
If any time is lost among the machines in a Spanner cluster, the whole concept of consistency could be at risk. Wherever a transaction happens, Spanner has to reconcile that change across all of the nodes based on timestamp and if the timestamps were inconsistent across the cluster it would be a FUBAR situation. Google engineers implemented their own API and GPS/analog clock based system to overcome any possible time inconsistency.
SQL Syntax
The Spanner paper goes into great detail about the importance of supporting a SQL query language. While it may seem like a small thing, SQL is the most underrated aspect of most data retrieval systems. Consider these anecdotes. Spark SQL is by far the most popular feature in Spark. KSQL, the Kafka SQL syntax joined the Kafka ecosystem with much fanfare. The N1QL query language on Couchbase allows SQL on documents and is a vast improvement over querying with Javascript.
I won’t understate how complicated SQL can be, but it’s true that anyone can learn the basics of SQL. Everyone cannot learn the basics of querying a graph by contrast (I’m still learning after a year). The paper is sparse on details about the query language and the optimizations therein. This seems to be mostly a user experience consideration from the designers of the system. That being said, from reviews I've read of Cloud Spanner some aspects of their SQL implementation leave a bit to be desired.
It is worth noting that Google does not claim Spanner is a Postgres-compliant query language so most criticisms are probably unwarranted.
Future
The promise of Spanner
There has already been a bit said about Spanner's impact on the big data ecosystem. Some are going as far as saying the Hadoop ecosystems days are numbered. I think this is a bit rash, but I do see this as an industry shifting piece of technology. As I talked about in earlier sections, SQL drastically simplifies everything for this ecosystem. Application developers, Data Scientists, Business Intelligence analysts, Systems engineers and Data Engineers all understand SQL, which shouldn't be overlooked. Traditional data sharing was hard, but this could be a lot easier.
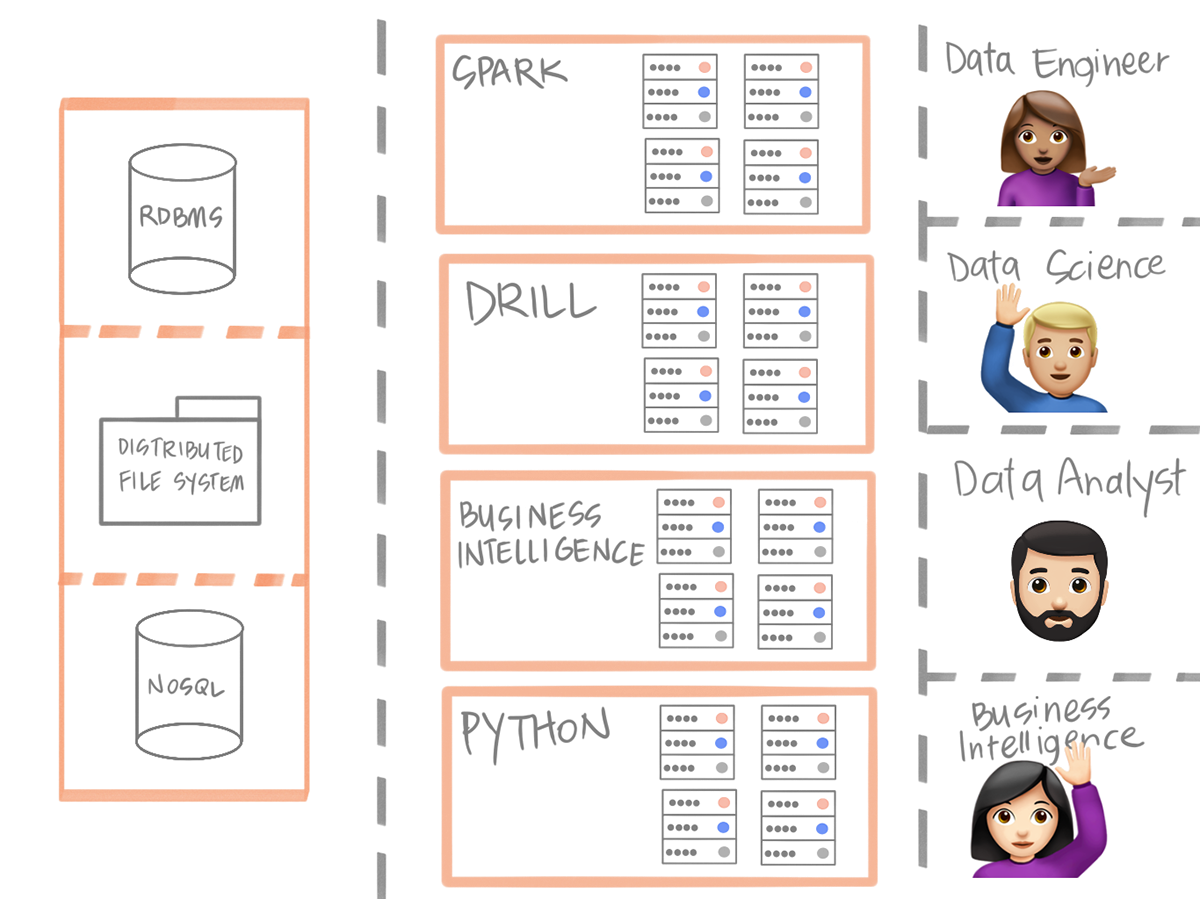
The complexity of running multiple environments for different stakeholders of data
With Spanner, much of the necessity for ETL for the sole purpose of summarization of data for different silos are gone. You don't need to translate data from S3 to a MySQL instance for example. That being said, we're still pretty far away from this "golden age." You'll notice that the schema type mentioned in the paper is "table-like" and that behind the scenes there is a key-value store at play. Early reviews of commercial offerings of Cloud Spanner have noted the difficulties of it not supporting all of what you'd expect from a relational database. The same has been said of CockroachDB, a Cloud Spanner competitor.
I think Spanner's best hope for adoption is by having an Open Source system out there. CockroachDB is pretty much that, but I assume more implementations are coming up. Maybe Google will donate Spanner to the CNCF or Apache Software Foundation. Whatever it is, I think Open Source will accelerate the adoption of Spanner. There will be a Spark connector, Flink, JDBC connectors etc. I'm looking forward to its adoption and the future.
Errors
If I misinterpreted any of the details about the Spanner paper and implementation, please get in contact with me on Twitter or via email.
Thanks
Special thanks to @vboykis for feedback and edits on this post.